
Provenance of simulation and data analysis workflows
Introduction
Computational provenance is a record of all the steps in a computational scientific workflow, including the code that was run, input data, the computational environment (hardware, OS, compiler versions, library version...), the person who performed each step, and output data.
Capturing computational provenance facilitates:
- reproducibility of results
- management and tracking of workflows/projects by the scientists/engineers involved
- evaluation/review by other scientists and engineers
Standards
The W3C PROV standard provides a data model and related tools for provenance interchange on the web. The following diagram shows the three base classes of the PROV data model: Entity, Activity, and Agent. These three classes form the basis for the representation of provenance in the EBRAINS Knowledge Graph: every node in the KG has a type which is a subclass of one of these base classes.

Storage of provenance in the Knowledge Graph
We present here the current schemas for representing (a) data analysis and (b) simulations in the Knowledge Graph. These schemas will need to be extended to cover neurorobotics simulations, and probably a more explicit representation of pipelines/workflows (the chaining together of multiple analysis / simulation stages) will be needed.
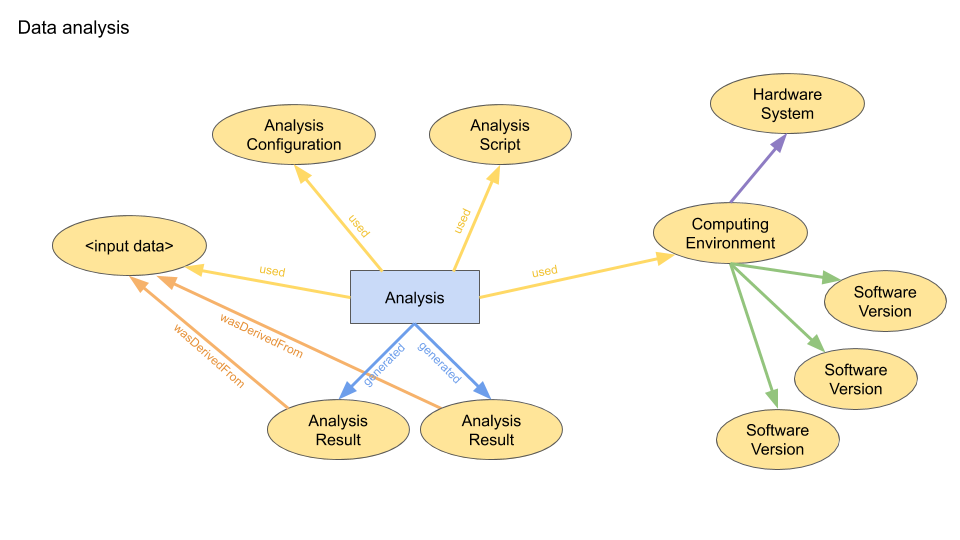
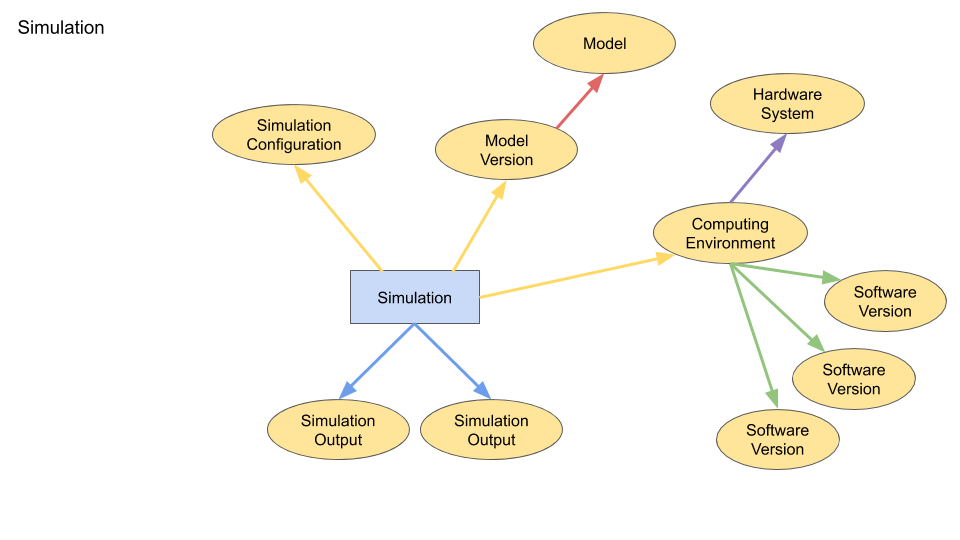
(note that the diagrams do not show Agents; the person who launched each analysis/simulation activity is linked to the activity with a wasAssociatedWith connection).
Tools for automated capture of provenance
Issues to discuss:
- on different systems:
- HPC systems
- neuromorphic systems
- Jupyter notebooks
- users' own computers
- prospective/pre-emptive vs run-time provenance capture
- capture of metadata vs capture of artefacts
Communication between computer systems and the KG
Two issues arise:
(i) fine-grained provenance information may need to be obtained on compute nodes, which may not have network access;
(ii) failures of provenance upload should not cause the workflows to fail;
An overall solution for both of these issues would perhaps involve a local cache and later synchronization.